微软全华班放出语音炸弹!NaturalSpeech语音合成首次达到人类水平
发布时间:2022-05-29现在很多视频都不采用人类配音,而是让「佟掌柜」、「东北大哥」等角色友情客串,在读起文本来还真有点意思。
相比之前机械化的电子音来说,文本转语音(text to speech, TTS)技术近年来取得了很大进展,但目前来说,合成的语音听起来仍然是机械发声,和人类的语音还有一定差距。
问题来了:怎么才能判断一个TTS系统达到了人类水平?
最近微软亚洲研究院和Azure语音团队共同发表了一篇论文,通过测量结果的统计意义衡量TTS系统和人类之间的差距,并提出一个端到端的TTS模型NaturalSpeech,首次将语音合成技术抬到人类水平。

论文链接:https://arxiv.org/pdf/2205.04421.pdf
演示网站:https://speechresearch.github.io/naturalspeech/
在demo里,可以明显感觉到合成的语音没有一丝「机器人」的感觉。
NaturalSpeech合成的句子与人类录音的对比参见链接:https://mp.weixin.qq.com/s/Dp817n04acU3MGkFM-sG1A
不过从音频的时长来看,语速上还是有一些细微差别。

文章发出后在reddit上引发热议,有网友表示结果真是难以置信!求代码,求模型。不过还不知道对于新的说话人是在预训练模型基础上微调还是需要重新训练。

也有网友评价生成质量真的很好,但韵律上并不总能保证正确,想修复这个问题可能需要AI模型理解句子的语义才行,所以他表示对纯粹的TTS模型并不抱太大期待。
即便人类朗读文本时也会出错,尤其是在读一些陌生领域的文字时。比如新闻播音员用机械的声音播报,其中一个原因就是他们不必完全理解新闻内容。
所以在韵律的掌控上可能是TTS系统下一步主攻的方向。
论文的通讯作者为谭旭,目前是微软亚洲研究院机器学习组的主管研究员,研究方向为深度学习、自然语言处理、语音、AI音乐、AI内容生成等。发表学术论文70余篇,引用量2600+,在机器翻译、预训练、语音合成、AI音乐创作等领域的研究在学术界和工业界产生广泛的影响力。

语音合成首次达到人类水平
构建具有人类水平质量的TTS系统一直是语音合成领域从业者的梦想。虽然目前的TTS系统达到了较高的语音质量,但与人类的录音相比,仍然有明显的质量差距。
不过在开发模型之前,先需要回答几个问题:
1. 如何定义文本到语音合成中的人类水平质量?
2. 如何判断一个TTS系统是否达到了人类水平的质量?
3. 如何建立一个TTS系统以达到人类水平的质量?
研究人员将「人类水平」定义为:如果一个TTS系统生成的语音的质量分数与相应的人类录音在测试集上的质量分数之间没有统计学上的显著差异,那么这个TTS系统在这个测试集上达到了人类水平的质量。

通过统计检验,就可以将「水平」转为一个可比较和可测量的数字。
这种方式测量出一个TTS系统在测试集上达到人类水平,并不是说一个TTS系统可以超越或取代人类,而是说这个TTS系统的合成质量在这个测试集上与人类的录音没有区别。
定义好评价指标,下一步就是搭建模型。
文章提出的NaturalSpeech模型是一个完全端到端的模型,从文本直接生成声音波形。
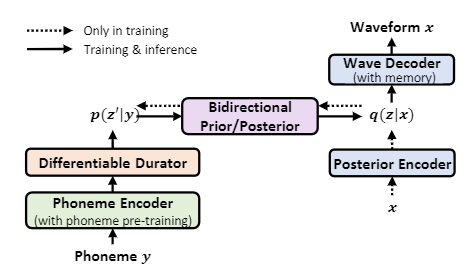
整个模型架构受到了图像和视频生成模型的启发,NaturalSpeech也利用VAE将高维语音压缩成帧级表征(即从后验分布中采样)用来重建波形。
为了能够从TTS的输入文本中生成条件波形,NaturalSpeech从音素序列中预测帧级表征,然后通过梯度传播来优化。
首先,为了学习到一个更好的音素序列表征以便更好地进行先验预测,NaturalSpeech在一个大规模的文本语料库上使用音素序列的遮罩语言模型对音素编码器进行预训练。

以往的相关工作主要是在字符或者词级别进行预训练,然后将预训练的模型应用于音素编码器,结果导致了训练测试不一致的问题,而直接使用音素预训练的相关工作往往由于音素词汇量太小,实际性能主要受到容量限制。
为了避免这些问题,NaturalSpeech利用混合音素预训练,同时使用音素和超音素(相邻的音素合并在一起)作为模型的输入。
当使用遮罩语言建模时,会随机maskd掉一些超音素标记及其相应的音素标记,并同时预测被mask的音素和超音素。在混合音素预训练之后,再使用预训练的模型来初始化TTS系统的音素编码器。
在第二步,由于后验是在帧层面,而音素先验是在音素层面,所以需要根据音素的持续时间扩展音素先验,以弥补长度差异。
NaturalSpeech利用一个可微分的durator来改善持续时间的建模效果,可以减少之前时长预测中的训练与推理不匹配的问题。
并且能够更好地以灵活的方式使用持续时间,而非硬性扩展,能够减少不准确的时长预测带来的副作用。
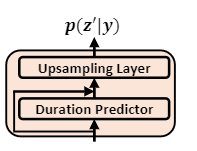
主要包含三个模块:
1. 持续时间预测器。建立在音素编码器的基础上,用来预测每个音素的持续时间;
2. 一个可学习的上采样层,利用预测的持续时间来学习投影矩阵,将音素隐藏序列从音素级扩展到帧级。
3. 在扩展的隐藏序列上有两个额外的线性层用来计算均值和方差。
第三步为一个双向的先验/后验模块来加强先验和简化后验。
因为从语音序列获得的后验和从音素序列获得的先验之间存在信息差距,所以NaturalSpeech选择flow模型作为双向先验/后验模块,因为它很容易优化,而且有很好的可逆性。

通过使用后向和前向损失函数,在训练中考虑了flow模型的两个方向,可以减少以往flow模型在后向训练、前向推理时的训练与推理不匹配现象。
第四步,研究人员提出了一个基于记忆的VAE,通过Q-K-V注意力利用记忆库来减少重建波形所需的后验的复杂性。
原始VAE模型中的后验用于重建语音波形,因此比音素序列中的先验更复杂。
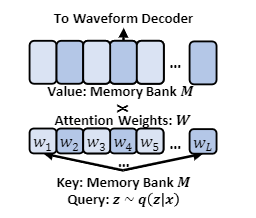
基于记忆的VAE模型可以简化后验预测,能够进一步降低先验预测的复杂度。这个模型设计的顶层思想就是不直接使用后验来波形重建,只使用后验作为query加入到memory bank中,并使用注意力的结果进行波形重建。
这样一来,后验只是用来确定memory bank中的注意力权重,因此大大简化了计算过程。
总的来说,NaturalSpeech在模型架构上主要有三大优势:
1. 减少了训练与推理过程的不匹配问题。
因为模型是直接从文本中生成波形,并利用可微分的持续时间来确保完全的端到端优化,可以减少级联声学模型/编码器和显式持续时间预测中的训练/推理不匹配问题。
不过需要注意的是,尽管VAE和flow本身就有训练-推理不匹配的问题,但文章通过修改原始模型的损失函数,一定程度上缓解了这个问题。
2. 缓解了一对多的映射问题。
与以前使用reference encoder或音高/能量提取进行变分信息建模的方法相比,NaturalSpeech中VAE的后置编码器更像是reference encoder,可以提取后置分布中所有必要的变分信息。
为了确保先验和后验能够相互匹配,模型使用记忆VAE和双向先验/后验模块中的反向映射来简化后验,并且用音素预训练、可微分的durator和双向先验/后验模块中的前向映射来增强先验。
3. 增强表征能力。
模型利用大规模的音素预训练从音素序列中提取更好的表征,并利用生成模型(Flow、VAE、GAN)捕捉语音数据分布,可以提高TTS模型的表征能力,从而获得更好的语音质量。
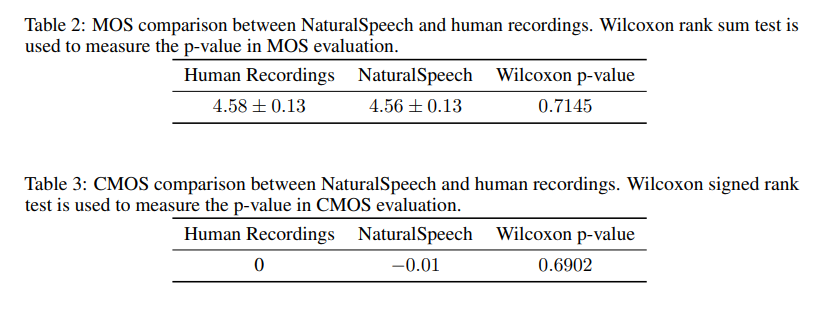
实验评估采用了流行的LJSpeech数据集,实验结果可以看到NaturalSpeech在句子水平上实现了对人类录音的-0.01CMOS(可比较的平均意见得分),Wilcoxon测试的p-value为0.05,表明在这个数据集上首次与人类录音没有统计学上的显著差异。
来源:新智元
